Flow
Anyone who has coded long enough has likely experienced what is commonly called flow, a state of intense focus, in which one is fully immersed in an activity. Being in a state of flow, one becomes more productive1, ideas become clearer, and good, elegant solutions to complex problems tend to come easily. Unfortunately, interruptions and changes of context can break this state of deep focus, and regaining it can take a (several minutes) long time. Again, this is likely a well-known issue for developers: your deep focus vanishes the minute a colleague asks a question, or your phone beeps, etc.
Since being in flow is a good thing™, it stands to reason that anything that helps maintain that state is probably a useful tool to have, and things that disrupt it are probably best avoided.
Caveat Lector
In what follows I'll be making fairly strong assertions that are colored by my experience, my preferences, and my way of developing software. Some of those may or may not match your own, and you will possibly disagree with some of the stuff below. I hope you do, however, take away a clearer idea of the benefits of working with a proper REPL.
Tools and Their Impact
In most commonly used programming languages, development follows a write-compile-run/test cycle2. This implies changing context at least once (to compile and run), most likely twice (if writing tests concurrently with the code).
For example, if working with Java or C#, you might write some method, and in order to test it, you will need a suitable test and possibly a test harness. The order in which you do these is not really relevant to this argument, but in any case both will be needed. This usually implies waiting for the code to build (usually fast, but still not instantaneous), and then waiting for the test to run (again, this takes some time). While this can be mitigated in some cases by having a test runner in the background, watching for changes, it still requires context changes and some time.
In languages with a proper REPL, such as Clojure and Common Lisp, we can write, run and test our code without leaving our editor window, and seeing the results in-place, and what's more important, we can do that incrementally, at the expression level. This allows for an extremely fluid development experience, in which we can immediately see the results of the code we are writing.
For example, let's say that part of what you need to do involves a regex. Regexes are typically (for me, at least) tricky to get right, so I may want to test the regex as I write it, against a bunch of possible inputs. If I was doing this in C#, I would probably write out my regex candidate, along with some scaffolding for the method I needed the regex for (if not the whole thing), plus one or more tests to check that the regex works as intended. Then I would run those tests (which takes some time), wait for them to finish, and look at the results to see if it needed more tweaking.
If I was working in Clojure, I would write out the regex, insert a
rich comment form mapping something like re-find over a series of strings I
want to match against, evaluate that, and fix as needed.
For example, let's say I need to match the strings "abctotod" "ab f" "ctotodfg"
"ac d" "cd". I may write out my regex and try it:
(comment
(let [rx #"[abc]+.*[def]$"
targets ["abctotod" "ab f" "c totodfg" "ac d" "cd"]]
(map (partial re-find rx) targets))
;; => ("abctotod" "ab f" nil "ac d" "cd")
,)
I will immediately notice it's wrong (note that the evaluation occurred directly from the actual buffer I'm coding in, and the results were inserted as a comment by my editor tooling, this is a keystroke away), and I can fix it there on the spot, without switching context:
(comment
(let [rx #"[abc]+.*[defg]$"
targets ["abctotod" "ab f" "c totodfg" "ac d" "cd"]]
(map (partial re-find rx) targets))
;; => ("abctotod" "ab f" "c totodfg" "ac d" "cd")
,)
This code can also be trivially extracted to its own test.
(deftest regex-test
(let [rx #"[abc]+.*[defg]$"
targets ["abctotod" "ab f" "c totodfg" "ac d" "cd"]
result (map (partial re-find rx) targets)]
(is (true? (every? some? result)))))
Top-down, bottom-up, inside-out
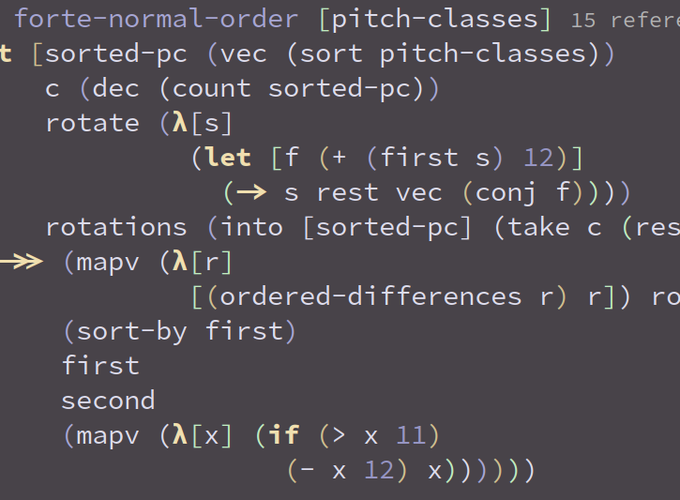
Lisps in general, and Clojure in particular, provide you with very flexible ways to think about and develop your software. I most often find myself working top-down when designing software, and implementing with a mix of bottom-up and top-down approaches. For example, once I have an idea of how an API should work and look like, I will start working from the data model, implementing the transformations needed to work the data I'm getting as arguments into the data I want to return as a result. This will often mean writing small functions (usually lambdas) to perform step-wise transformations on the data. I will generally use a threading macro to chain these together, and after verifying that they produce the desired outcome, I may swap the threading macro for a transducer-based solution, if it makes sense. Doing this while connected to the REPL, allows me to see the actual data transformation steps, and fix or modify them on the fly.
Of all the approaches I've used for developing software, this is the one I've found to be most comfortable, and also the one I'm most productive with, as there is basically no context switching between programming and testing. It all happens at once, in the same place.